|
|
Loading...
Searching...
No Matches
|
|
Internally, radar data is stored in a tree-like hierarchical structure very analogous to that of Hierarchical Data Format (hdf5) itself. Rack also takes advantage of the OPERA Data Model (ODIM, http://eumetnet.eu/wp-content/uploads/2017/01/OPERA_hdf_description_2014.pdf), an encoding and naming policy applicable in HDF5 for different types of radar data like azimuthal scans, polar products and Cartesian images .
In Rack, an HDF5 file is primarily stored using drain::Tree<T> structure, a tree where each node essentially consists of a data array and a map of attributes. The data array is implemented with drain::Image, an image class based on std::vector<T>. The images can use any storage type from unsigned char to \d double . The attributes are stored as a drain::VariableMap , which is essentially an stl::map<T> of references to scalar variables, arrays, and strings (std::string). Practically, in each node either the data array or attributes are applied (ie. non-empty). Specifically, /datasetN , /dataN , /what , /where , and /how Groups contain only attributes but the data is empty whereas in /data Group the data array is non-zero but the attribute map is empty.
For anomaly detection and removal as well as for meteorological products, all the processing is done in polar coordinate system, ie. the native system for radars. At the edges of the data arrays, coordinate handlers (drain::image::CoordinateHandler) quarantee that the coordinates are properly wrapped. This is needed by functions applying pixel neighbourhoods, such as those applying moving windows or spatial recursion.
Smoothing operations (drain::image::FastAverageOp, drain::image::FastMedianOp) apply rectangular moving windows which are updated incrementally, yelding a remarkable speedup. Functions not applying pixel neighbourhoods apply direct, one-dimensional memory iteration whenever possible.
The segment size analysis (drain::image::SegmentSizeOp) applies a semi-recursive floodfill technique, which combines a non-recursive horizontal traversal with a recursive vertical traversal; this keeps stack size small.
Internally some AnDRe detectors require that incoming data be in unsigned-char type with a fixed scaling (gain =1.0/250.0, offset =-32.0) and special codes (undetect =0, nodata =255). When needed, Andre performs this conversion automatically, storing the converted copy in a path suffixed with tilde '~'. These auxiliary data will not be included in output files unless a high debugging mode is selected with --verbose . The removal operations apply to the original data.
Instead of strict thresholding, the detectors apply frequently fuzzy functions ie. functions that map quantity ranges to continuous truth values between 0.0 (no) and 1.0 (yes). Then, conditions like "the dBZ is over 20" and "width of the speck is about 1500m" can be combined by multiplying associated fuzzy functions; the result is a combined truth value.
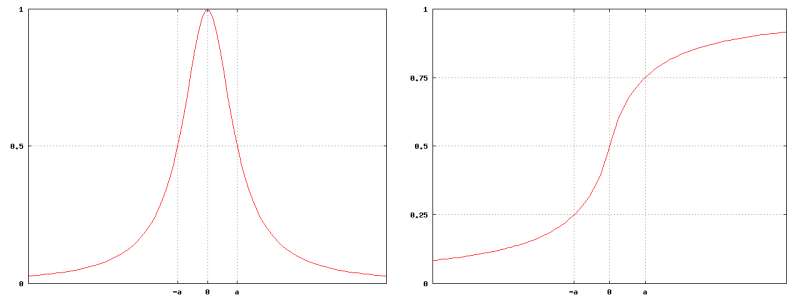
The typical fuzzy functions applied in AnDRe are fuzzy peak (drain::FuzzyPeak)
![\[
f_{\mathrm{p}}(x) = \frac{a^2}{a^2 + x^2}
\]](form_152_dark.png)
where 
![\[
f_{\mathrm{th}}(x) = \frac{1}{2} + \frac{x}{2(a + |x|)}.
\]](form_153_dark.png)
where
 1.9.8
1.9.8